Tomasz Zieliński
Jednym z bardziej spektakularnych przykładów chybionego tłumaczenia w branży IT jest „Darmowa ochrona danych jesień”, nazwa programu dołączanego do laptopów Della (rozwiązanie zagadki na końcu artykułu). Ktoś mógłby parsknąć i spytać, czy naprawdę przełożenie kilku zdań z angielskiego na polski jest aż tak trudne. Otóż – z całego procesu adaptacji oprogramowania na inny język ta czynność jest akurat najprostsza, za to sam proces jest wręcz najeżony przeszkodami.
W niniejszym tekście opiszę, dlaczego tylko dojrzałe organizacje tworzące software są w stanie prawidłowo ogarnąć nie tylko tłumaczenia (translation), ale także dwa pozostałe aspekty globalizacji (globalization): internacjonalizację (internationalization) oraz lokalizację (localization). Zdolni programiści nie wystarczą. Staranni i wnikliwi testerzy też nie wystarczą. Ani biegli tłumacze. Potrzebny jest zespół, który wie co i jak zrobić, aby było dobrze.
Ten artykuł – publikowany jednocześnie w serwisach Informatyk Zakładowy oraz localization.pl – opisuje przyczyny pomyłek, kiksów i usterek, które mają miejsce gdzieś w świecie każdego dnia. Ich lista nie jest pełna ani kompletna, zaś każdy, kto pracował w międzynarodowym zespole tworzącym oprogramowanie, mógłby dorzucić coś od siebie. Motto: „lokalizacja jest jak kanalizacja — nikt o niej nie mówi, dopóki działa” (h/t Marta Bartnicka).
L10N, I18N, G11N oraz T9N
Tytuł rozdziału to skrótowce angielskich słów localization, internationalization, globalization oraz translation. Co oznaczają te pojęcia? Prześledźmy to na przykładzie amerykańskiego sklepu internetowego, który chce sprzedawać swoje towary do Polski.
Pierwszym krokiem może być tłumaczenie (translation, t9n) czyli to, co robią tłumacze – dostają oni jakiś tekst po angielsku i produkują tekst o takim samym znaczeniu w języku polskim. Zamieniają „welcome” na „witaj” i „shopping cart” na „koszyk”. Na razie jest łatwo.
Klienci z Polski zaczną jednak narzekać, że polski odpowiednik ceny „$10.00” nie powinien brzmieć „zł39.53” tylko “39,53 zł”. Podobnie data wysyłki czytelna dla Polaka to nie „03/31/2021” tylko “31.03.2021”. Wchodzi nam drugi element, czyli internacjonalizacja (internationalization, i18n) – umożliwienie dopasowania interfejsu użytkownika do konwencji stosowanych w kraju, regionie czy w normach języka którym włada klient.

Gdy te problemy zostaną rozwiązane, zacznie się narzekanie na funty, cale i stopy kwadratowe. Co to za pomysł, by osiągi samochodu podawać w milach na galon, przecież spalanie mierzymy w litrach na 100 km. A w ogóle to nikogo nie obchodzi amerykańskie Święto Dziękczynienia, my tu kupujemy prezenty na Mikołajki. Takie wyzwania stają przed lokalizacją (localization, l10n), w ramach której dokonujemy dostosowania do kultury, tradycji, miar, metryk itd.
W cyferkowych skrótowcach mamy jeszcze a11y czyli dostępność (accessibility), ale ten temat wykracza poza ramy dzisiejszej blogonotki.
O czym będzie ten tekst?
Większość problemów związanych z lokalizacją bierze się z faktu, że większość z nas zna dobrze tylko jeden lub dwa systemy kulturowe. Tak po ludzku nie przychodzi nam do głowy, że coś oczywistego może po drugiej stronie świata działać zupełnie inaczej. Zresztą – nawet na naszym własnym podwórku dzieją się rzeczy, które widzimy a których nie rozumiemy. Wyznawcy prawosławia mieli wolne 6 stycznia nie dlatego, że świętują wigilię Bożego Narodzenia w styczniu, ale dlatego, że według kalendarza juliańskiego wtedy właśnie jest 24 grudnia – przez setki lat daty w sąsiadujących państwach różniły się o kilkanaście dni, z wszystkimi niewygodami z tego wynikającymi. Rewolucja październikowa miała miejsce w listopadzie, wiedzieliście?

Będę pisał o tym, że programowanie komputerów jest dziś na tyle skomplikowane, że jeden człowiek może ogarnąć jedynie niewielki wycinek branży. Jeśli postawimy obok siebie ludzi programujących systemy komunikacyjne satelitów, sterowniki do wyświetlaczy LCD, hurtownie danych do e-commerce i gry mobilne to… nie będą oni mieli ani jednego wspólnego zawodowego tematu. Ich narzędzia i metodyki są tak odmienne, że żaden nie będzie w stanie opowiedzieć z głowy o pracy drugiego, nie mówiąc o jego zastąpieniu.
Będzie też o tym, że tłumacze rzadko rozumieją zawiłości związane z tworzeniem oprogramowania, zaś programiści zbyt często prezentują postawę arogancką i roszczeniową – zrażając do siebie współpracowników spoza kręgu osób „technicznych”. W rezultacie nawet najbardziej staranny tłumacz – zwłaszcza wynajęty do jednorazowego zlecenia – może nie być świadom wymogów stawianych przez dany framework, język programowania czy system operacyjny. A szczegółów nie pozna, bo zminimalizuje kontakty z nieokrzesanymi bucami z IT.
Ustawienia regionalne
Jeśli pobłądzimy w ustawieniach Windows 10 odpowiednio głęboko, możemy natrafić na ustawienia regionalne. Jako Polacy, mamy w Polsce ograniczone zrozumienie dla różnorodności kombinacji „państwo-język-region”, bo nasz język jest jedynym językiem urzędowym w Polsce i nigdzie indziej. Pomyślmy jednak o następujących przykładach:
- Szwajcaria ma cztery języki państwowe (niemiecki, francuski, włoski i romansz).
- Język angielski ma ponad sto wariantów regionalnych, różniących się m.in. gramatyką, zapisem niektórych słów (color/colour), formatami daty lub godziny i innymi istotnymi detalami.
- Indie odnotowały 30 języków z ponad milionem użytkowników każdy i 122 języki z ponad 10 tysiącami użytkowników każdy.
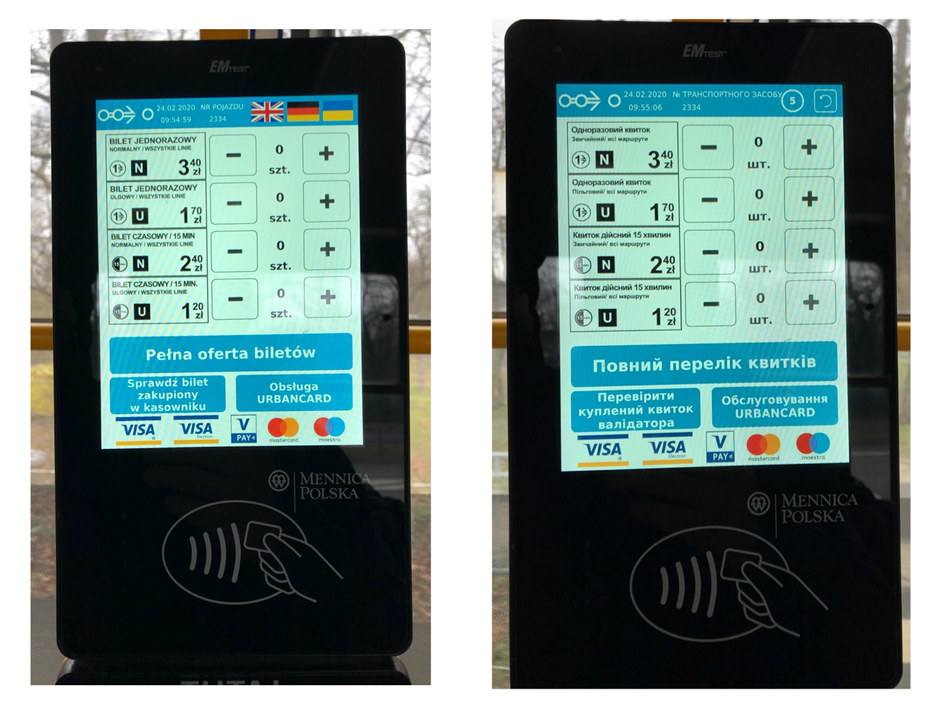
Jeśli zaczniemy eksperymentować z formatami liczb, dat i walut, szybko zaobserwujemy całą gamę możliwości. Oto przykłady wartości predefiniowanych dla języków polskiego (Polska), francuskiego (Francja) i angielskiego (USA):
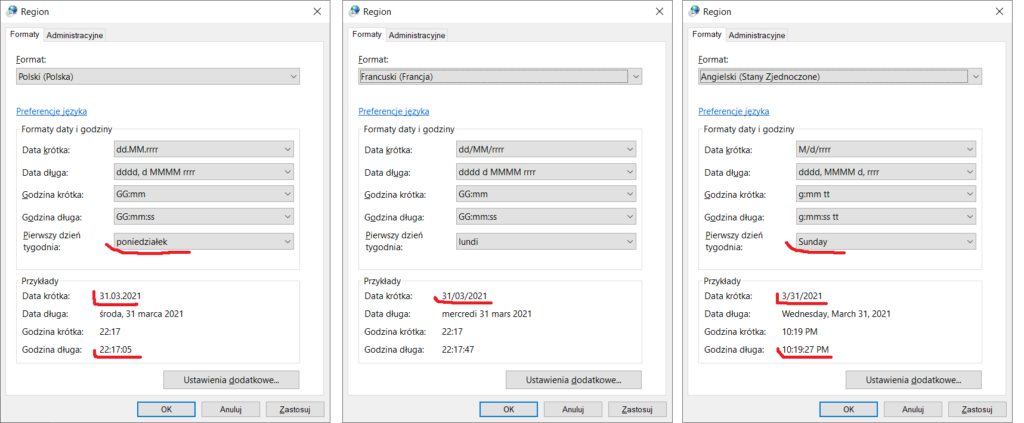
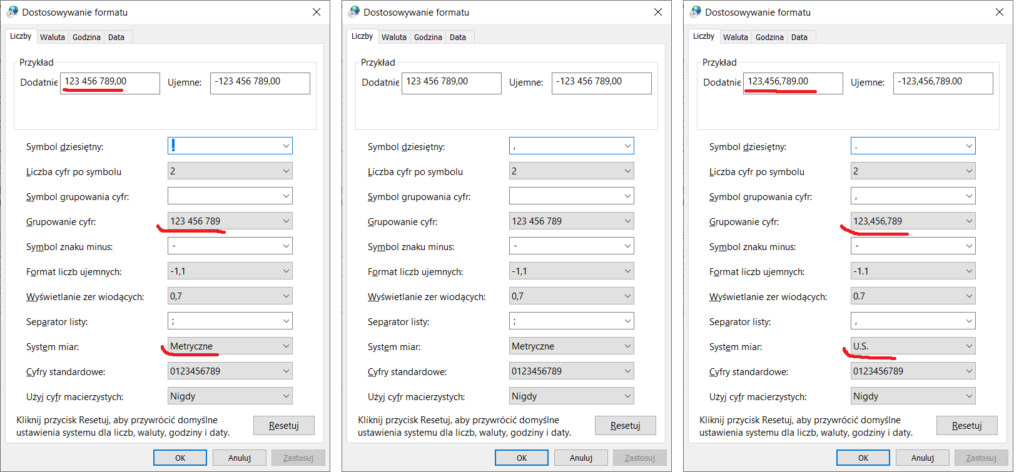
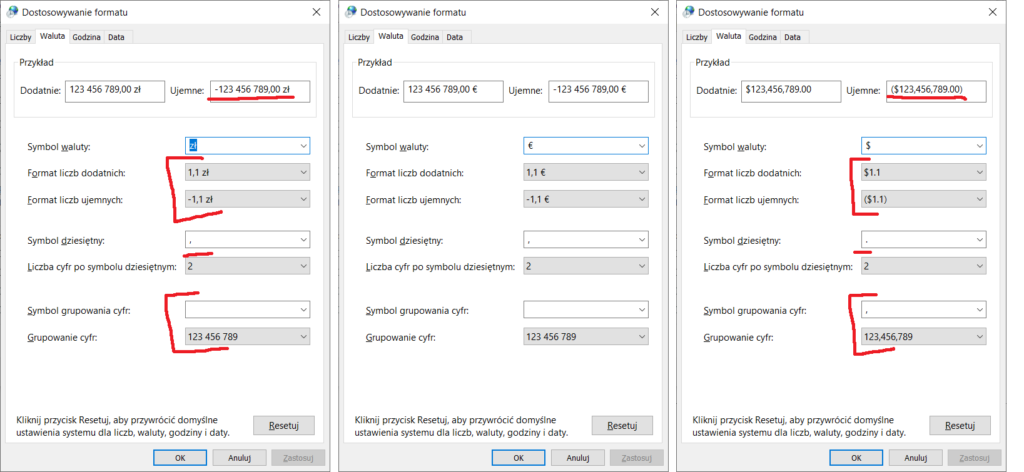
Różnice są naprawdę istotne. Francuski separator daty to nie „polska” kropka lecz ukośnik, w USA pierwszy w dacie jest miesiąc a nie dzień, ujemne kwoty pieniędzy (i tylko pieniędzy!) zapisuje się za oceanem w nawiasach, zaś separator oddzielający złotówki od groszy i euro od eurocentów to przecinek a nie kropka, jak w przypadku dolarów i centów. Pierwszy dzień tygodnia to u nas poniedziałek, w innych krajach niekoniecznie.
Mówicie, że skoro każdy ma po swojemu, to przecież nie ma problemu? Ha! Bo nie pracowaliście w międzynarodowej korporacji. Załóżmy, że dostajecie arkusze Excela od współpracowników z Filipin, Burkina Faso, Wysp Zielonego Przylądka i Pcimia. Waszym zadaniem jest zrobienie z tych danych zestawienia sprzedaży w kolejnych dniach miesiąca. Robi się ciepło, nie? Formaty dat, formaty liczb, formaty walut – czy Excel przeliczył wszystko jak należy? Czy każdy z zagranicznych pracowników miał prawidłowe ustawienia? A przecież mówimy o używaniu istniejącego oprogramowania, nie o podejmowaniu takich decyzji w odniesieniu do tworzonego softu…
Pół biedy, gdy chodzi o Excela – Microsoft to firma globalna i w swoim wiodącym produkcie zrobili wszystko jak należy. Trudniej robi się, gdy chcemy użyć polskiego oprogramowania księgowego (100% użytkowników w Polsce) z zagranicznymi ustawieniami regionalnymi. Dziesiętna kropka czy przecinek dziesiętny? Czy da się wpisać niewłaściwie? Jak zachowa się program? Czy po zapisie i odczycie danych widać to samo, czy coś po cichu zniknie? Jeśli zniknie, to obetnie część ułamkową czy pomnoży całość przez sto? A może dane zostaną zapisane, ale nie dają się odczytać?

A może system operacyjny i język programowania obdarzyły programistę warstwą kompatybilności z ustawieniami regionalnymi, która działa świetnie i której wystarczy nie zepsuć? A on o tym nie wiedział i zepsuł ją tylko raz i tylko w jednym miejscu? W tej opcji, której używa się raz na rok przy drukowaniu formularzy PIT?
Tego tematu na pewno nie wyczerpiemy, więc na zakończenie obrazek:

Co to za robaczki? To są, moi drodzy, cyferki „sześć” w różnych alfabetach. Unicode zna 65 odmian szóstki, a to i tak tylko warianty w kategorii „cyfra dziesiętna”. Pytanie, na które nie oczekuję odpowiedzi: w ilu znanych wam programach da się używać zamiennie szóstek innych niż pierwsza z lewej?
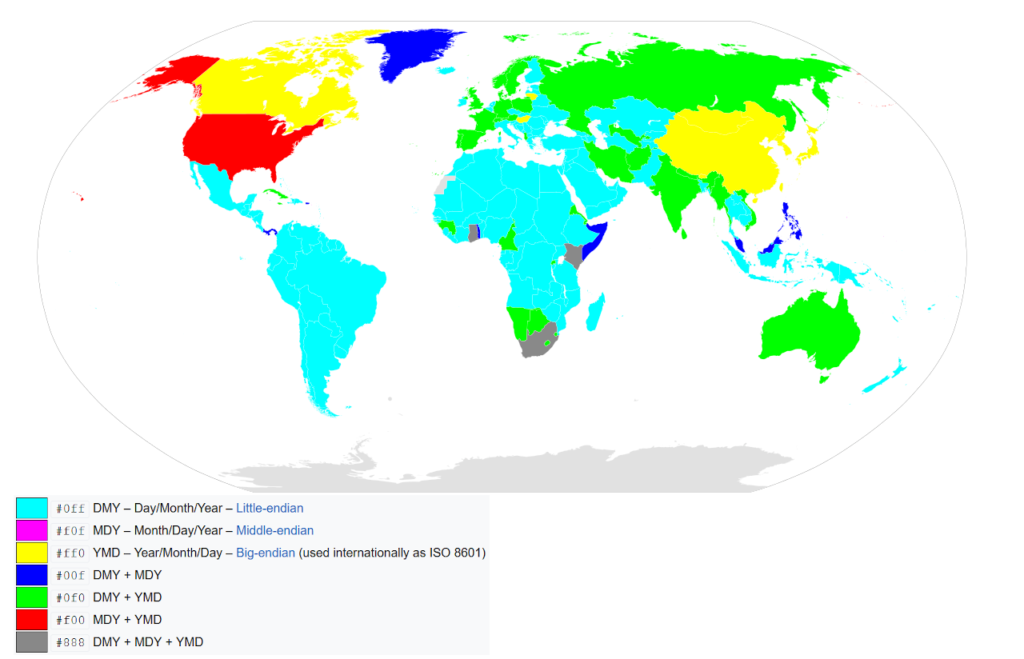
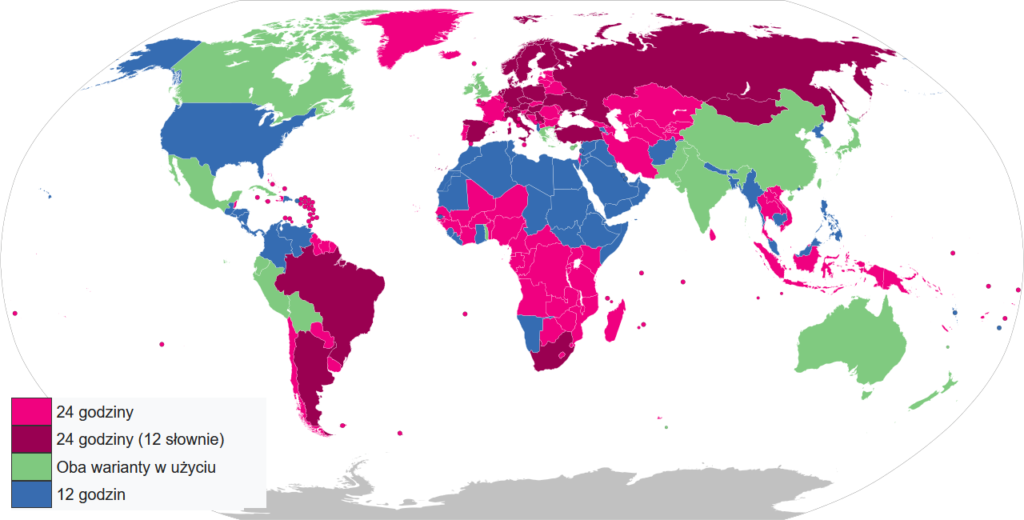
Formaty daty i godziny, GMT kontra UTC
Obsługa dat i godzin to jedna z trudniejszych rzeczy, jakie stają przed osobami projektującymi systemy IT. Nie dlatego, że jest trudna (choć temat jest złożony), ale z powodu zestawu pułapek, w jakie wpada każdy tworzący po raz pierwszy oprogramowanie działające w wielu strefach czasowych. W programie studiów informatycznych nic o tym nie ma. Albo trafimy do jednej z kilku globalnych korporacji i tam wchłoniemy wiedzę od kolegów, albo nie trafimy i wtedy mamy serię pomyłek i usterek.

źródło: archiwum prywatne, bo niby jakie inne?
O dacie i czasie w programowaniu prędzej czy później napiszę osobną blogonotkę, temat leży w notatkach od zawsze. Tymczasem zaś dwa obrazki pokazujące, gdzie co jest po naszemu a gdzie po ichniemu.
Byte Order Mark
Temat sposobów zapisu daty czy godziny każdy jako-tako rozumie, więc teraz dla równowagi stricte techniczna przyczyna problemów z obsługą plików tekstowych (TXT). Zacznijmy od wstępu fabularnego.
Pamięć komputerów podzielona jest na bajty, z których każdy może przyjąć jedną z 256 różnych wartości. Jeśli potrzebujemy zapisać w pamięci komputera większą liczbę, będziemy potrzebować więcej niż jednego bajtu. Jest kwestią umowy, jaką kolejność bajtów obierzemy. Procesory w komputerach wolą najpierw zapisać bajty oznaczające większą część liczby (little endian), ale procesory w komórkach mogą korzystać z odwrotnej konwencji (big endian, do wyboru).
Pamiętacie artykuł o emotkach i Unicode? Napisałem tam, że jeden znak ekranowy może być zapisywany przy użyciu wielu bajtów, no a właśnie powiedzieliśmy sobie, że różne procesory mogą robić to w różny sposób. Wystarczy przenieść plik z taką zawartością na komputer o innej konwencji zapisu i klops.
Problemom takim miał zapobiec tzw. BOM (Byte Order Mark), czyli kilkubajtowy nagłówek plików tekstowych jednoznacznie identyfikujący kolejność zapisanych bajtów. Dobrymi chęciami piekło jest wybrukowane – wszystkie porządne formaty danych (np. JPEG, ZIP i inne) używają zawsze jednej konwencji, niezależnie od architektury procesora i organizacji pamięci. W ciągu całej kariery nigdy nie trafiłem na sytuację, w której BOM decydowałby o interpretacji zawartości pliku.
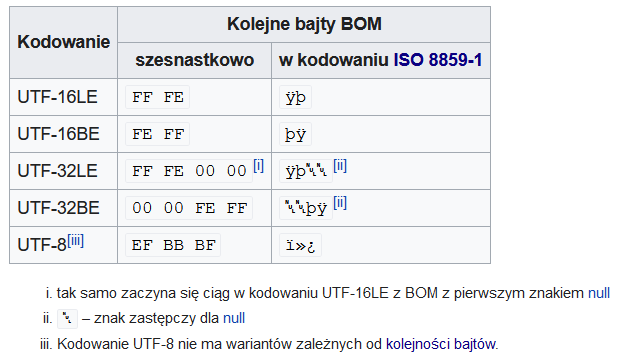
Bardzo wiele razy trafiałem za to na dokumenty tekstowe zaczynające się od ciągu znaków  – czyli od nagłówka BOM UTF-8 wyświetlanego przez narzędzie nieświadome jego istnienia i znaczenia. Jest to szczególnie uciążliwe, gdy programiści wymieniają z tłumaczami pliki zawierające teksty w obcych językach. Jeśli edytor tłumacza wymusza użycie BOM zaś środowisko programistyczne wyklucza jego obecność – mamy nawracające źródło problemów.
Sortowanie alfabetyczne
Co może być trudnego w sortowaniu alfabetycznym, pomyślicie? Przecież umie to każdy drugoklasista. Spoko! Proszę zacząć od alfabetycznego posortowania następującego zestawu literek „a” ze znakami diakrytycznymi.

Słabo? No jak to, przecież to tylko akut, grawis, cyrkumfleks, brewis, cedylla, precylla, makron czy dasja (jedno z tych słów wymyśliłem; dasz radę żyć z niewiedzą czy sprawdzisz je teraz jedno po drugim? napisz w komciu). Dobra, do rzeczy. Najsprytniejsi wykonają unik stwierdzeniem, że po to programujemy komputery, żeby robiły takie zadania za nas. No i spoko, tylko że reguły sortowania zależą od języka.
Serio, w polskim alfabecie mamy sekwencję „u – v – w”, za to w języku szwedzkim „w” jest równoważne „v”. Teraz zagadka – jeśli polska policja współpracuje ze szwedzką policją i mają listę ściganych przestępców sortowaną po nazwisku, to czyje sortowanie wygrywa? W Polsce „ą” jest po „a”, jednak w języku francuskim literki z diakrytykami i bez są sobie równoważne, za to przegrywa ostatni diakrytyk (mamy więc: cote < côte < coté < côté). W języku estońskim litery „õ”, „ä”, „ö” oraz „ü” mają miejsca za „w”. Dziesiątki innych przykładów znajdziecie w Wikipedii.
Jak działają bazy danych? Proste – pozwalają na wybór reguł sortowania, jest ich ze czterdzieści (Polacy nie gęsi a swój collate mają). Chyba że policzymy osobno sortowanie uwzględniające lub ignorujące wielkość liter – wtedy ponad osiemdziesiąt. Jeśli zobaczycie kiedyś „ą” za „z” – wiedzcie, że w wielu systemach sortowania „gołe” literki łacińskie stoją przed wszystkimi diakrytykami.
Unicode
Dobra wiadomość: kilkanaście lat temu standard Unicode wyzwolił nas od konieczności konwertowania dokumentów między różnymi stronami kodowymi, dzięki czemu możemy swobodnie mieszać teksty w różnych językach.
Zła wiadomość nr 1: ogonki w polskich literkach będą zazwyczaj na swoim miejscu, więc łatwiej przeoczymy inne usterki.
Zła wiadomość nr 2: na styku wielu systemów informatycznych usterki lubią się kumulować – na obrazku poniżej mamy rymowany wierszyk o tym, jak literka „ó” w pięciu krokach zmienia się na etykiecie adresowej w potwora: „&ATILDE;&SUP3;”

Wyzwań znajdziemy więcej. W artykule o emotikonkach pokazałem, że tekst o dokładnie takim samym wyglądzie (i znaczeniu!) można w Unicode zapisać na wiele sposobów. Nie spodziewajcie się spójnej normalizacji ani normalizacji w ogóle.
Minus, myślnik, pauza, dywiz i półpauza
W kodzie źródłowym programiści używają tylko znaku “minus” (znak ASCII nr 45, patrz tekst o Base64). Zgadniecie, którym znakiem zastąpią dywiz, pauzę i półpauzę, gdy przyjdzie do edycji tekstu? Tak. Jedynym, jaki znają. Minusem. Zgadniecie, jakimi znakami zastąpią minusy kształceni w naukach humanistycznych tłumacze? Tak. Całym zestawem – myślnikiem, dywizem, pauzą i półpauzą.
Jednych i drugich trafi po drodze szlag, bo muszą przecież odkręcić omyłki wynikające z prostactwa i nieuctwa drugiej strony. A spór ten trwać będzie po wiek wieków – chyba że uzgodniona zostanie wspólna konwencja. Porada ogólna: w umowie dotyczącej tłumaczenia oprogramowania warto uwzględnić nie tylko wzorcowy słownik, ale także gramatykę (angielski w różnych rejonach świata różni się) i techniczne warunki współpracy.

źródło: 20,000 Leagues Under the Sea oraz 20 000 mil podmorskiej żeglugi. Czy ktoś czytuje jeszcze Verne’a? Czy ktoś czytuje jeszcze podpisy pod obrazkami? Piszcie w komciach!
PS: tak, dwa słowa w tytule tej sekcji oznaczają to samo. Jeśli wiesz, które – za przygotowanie do lekcji dostajesz plusa (znak ASCII nr 43).
PPS: chyba że w pierwszym Postscriptum był żarcik, wtedy nie dostajesz.
Cudzysłowy
Tu robi się trudniej, bo zasady użycia cudzysłowów różnią się bardzo w różnych krajach – zależą od języka, gramatyki, przyjętych form i zwyczajów. Przykłady w angielskim i polskim tekście obrazek temu. Wiele narzędzi rozumie tylko jedną formę i spróbuje „naprawiać” usterki, które często usterkami nie są. Co gorsza, zachowanie wielu z nich będzie zależało od wersji językowej oprogramowania, systemu operacyjnego, ustawień językowych, ustawień lokalizacyjnych lub wypadkowej wszystkich poprzednich elementów.
Aby daleko nie szukać – ten blog chodzi na WordPressie i o ile przykładam uwagę do względnej poprawności cudzysłowów, które z całym tekstem kopiuję z Google Docs, to wszelkie formy poziomych kresek puszczam na żywioł. Literówek czepia się wiele osób, błędnych cudzysłowów i myślników – nikt. Oczywiście ktoś gdzieś cierpi, ale robi to w milczeniu (mogę z tym żyć).
Do rzeczy. Ponownie – w kodzie źródłowym używamy zwykłych cudzysłowów ASCII (kod 34), czasem apostrofu (kod 39), raz na rok tego śmiesznego odwrotnego apostrofka na lewo od klawisza “jeden”, jego kod ASCII to 96 (grawis albo grave accent).
W prawdziwym życiu bywa jednak trudniej. Ten kawałek będzie ilustrowany obrazkami – nie podejmuję się wklepania tych wszystkich zabawnych znaków do WordPressa. Na styku gramatyki i technologii mamy dodatkowo takie detale, jak niełamliwe spacje (specjalny znak, na którym nigdy nie nastąpi przejście do nowego wiersza) albo cudzysłowy w różnych konwencjach:
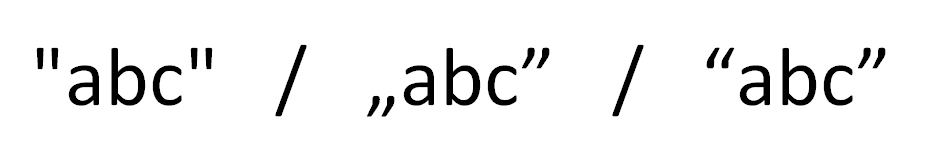
Wszyscy zaangażowani w tłumaczenia muszą wiedzieć, które cudzysłowy są „techniczne” czyli pozwolą językowi programowania ustalić początek i koniec napisu, a które mają trafić na ekrany komputerów lub komórek (nie każdej konwencji da się użyć w każdym środowisku). Tych pierwszych dotykać nie wolno, te drugie muszą być traktowane z dużą ostrożnością, bo niektóre programy narzędziowe wiedzą lepiej i na siłę modyfikują znaki lub – co gorsza – wstawiają lub usuwają ligatury.
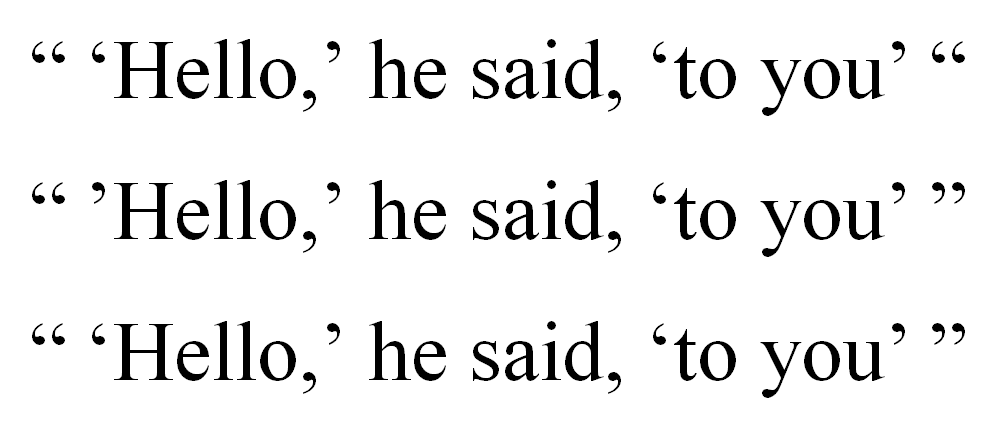
Ciekawostka – tylko jedna z trzech linijek na obrazku wyżej jest poprawna wg brytyjskich zasad interpunkcji.
Zanim zaczniesz chwalić się tą wiedzą, zdaj sobie sprawę z tego, że czytasz słowa napisane przez programistę, który w połowie lat 90. ubiegłego stulecia miał z polskiego naciąganą czwórkę, za to biegle copypastuje angielską Wikipedię. Tak, że ten. Równie dobrze poprawne mogą być dwie linijki lub żadna. Zależy, jak się wkleiło do Worda.
Nie możesz wierzyć we wszystko, co przeczytasz w internecie
Albert Einstein
Więcej prawdziwej wiedzy tutaj, tutaj albo tutaj.
Duże liczby czyli miliard dolarów kontra bilion dolarów
Podobno jeden obraz wart jest tysiąca słów, oto porównanie jachtów milionerów z jachtem miliardera:

O różnicach między nazewnictwem potęg liczby tysiąc pisałem w tekście „Kilobajt, megabajt, gigabajt, terabajt”: tam, gdzie większość Europy liczy „tysiąc, milion, miliard, bilion, biliard, trylion”, kraje angielskojęzyczne używają wersji „tysiąc, milion, bilion, trylion, kwadrylion, kwintylion”.
Tę wiedzę wypada posiąść. Zbyt często widzimy w TV lub słyszymy w radiu niedouczonych dziennikarzy mówiących coś w rodzaju „budżet NASA to 22 biliony dolarów”. Chodzi o oczywiście o rodzime miliardy a cały budżet federalny USA to 6,5 tysiąca miliardów dolarów (czyli 6 „naszych” bilionów). W codziennym życiu nie mamy zbyt często do czynienia z tak dużymi liczbami, ale w tekstach o objętościach dysków twardych albo odległościach w kosmosie trzeba zachować czujność.
Dygresja: czasem trafiamy na niedouczonych blogerów, którzy odmieniają słowo „radio”, ale to oni mają rację (sprawdzić, czy nie ejżur).
XML, JSON i inne potworki
Dobrą praktyką, dziś wymuszaną przez wiele środowisk programistycznych, jest wydzielanie wszystkich napisów wyświetlanych na ekranie do osobnych plików z zasobami. Może to wyglądać na przykład tak:
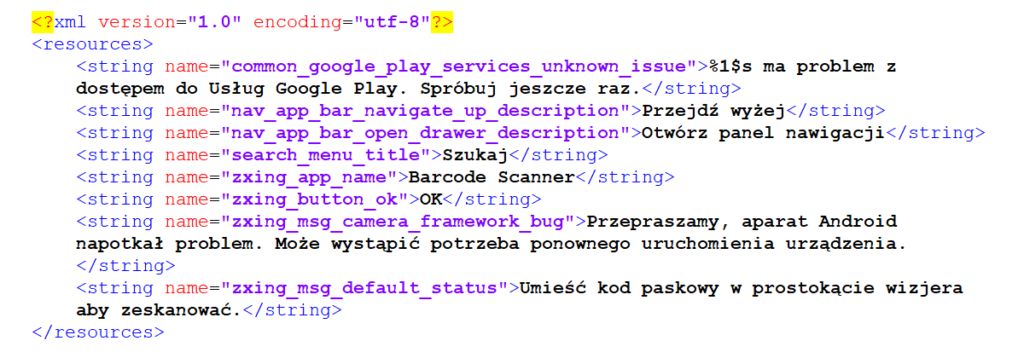
Jeśli tłumacz dostanie taki plik do tłumaczenia, musi znać co najmniej listę znaków zabronionych, na którą składają się znaki ’<>&”. Zamiast nich trzeba używać zamienników takich, jak > albo &. Powinien też wiedzieć, kiedy zamknąć wynikowy napis w sekcji CDATA. Oczywiście taki tłumacz powinien stosować specjalizowany edytor XML, aby uniknąć błędów składni. Słowem – wysyłanie do niezaprawionego w lokalizacyjnych bojach tłumacza gołych plików XML to zły pomysł, bo jest to format danych do przetwarzania maszynowego a nie edycji przez człowieka.
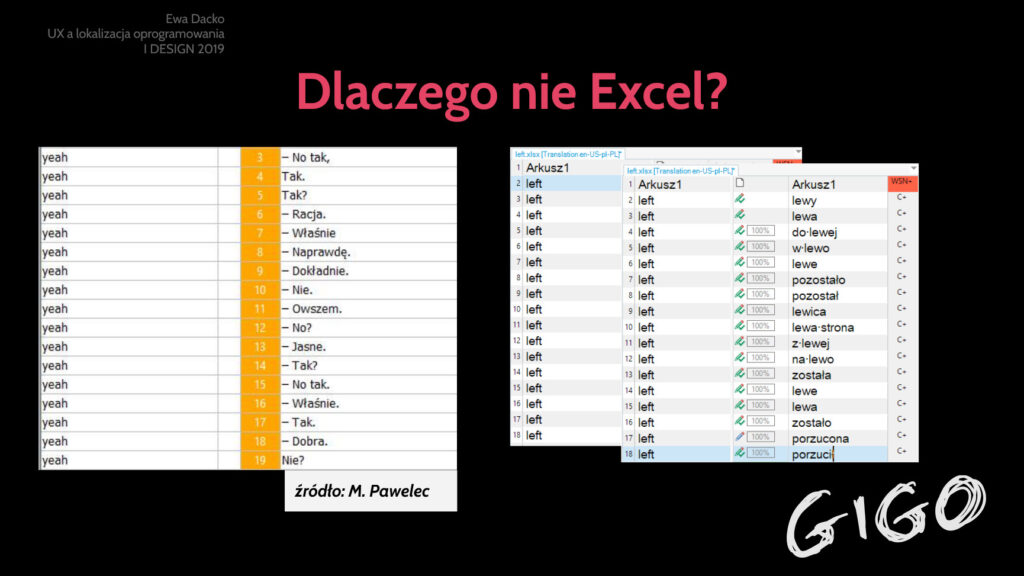
Oczywiście znacznie gorszym pomysłem będzie dostarczenie fraz do tłumaczenia w Excelu. Wiecie, takim posortowanym alfabetycznie i pozbawionym kontekstu. To gwarantowany przepis na frustrację tłumacza, irytację testerów i rozpacz użytkowników.
Liczebniki i określanie mnogości
Niektóre dzikie ludy stosują liczebniki „jeden, dwa, wiele”. Moglibyśmy nauczyć się od nich… wiele (śmiech z taśmy). Tymczasem jednak mamy to, co mamy, czyli na przykład język polski, w którym liczebność wpływa na formę rzeczowników i przymiotników. Cytat z Rady Języka Polskiego:
liczebniki 2, 3, 4 oraz liczebniki, których ostatnim członem jest 2, 3, 4 (czyli np. 22, 23, 24, 152, 153, 154 itd.) łączą się z rzeczownikami w mianowniku liczby mnogiej, np. trzy koty, dwadzieścia cztery koty, sto pięćdziesiąt dwa koty. Liczebniki od 5 do 21 i te, które są zakończone na 5-9 (np. 25, 36, 27, 58, 69), łączą się z rzeczownikiem w dopełniaczu liczby mnogiej, np. pięć kotów, siedemnaście kotów, sto siedemdziesiąt siedem kotów. Należy też pamiętać o tym, że liczebnik dwa (i inne zakończone na dwa) ma formę dwie przy rzeczownikach rodzaju żeńskiego: dwie panie, dwadzieścia dwie bułki, sto czterdzieści dwie butelki. Wszystkie liczebniki mają ponadto odrębną formę przy rzeczownikach męskoosobowych, np.: dwaj, trzej, czterej panowie (albo: dwóch, trzech, czterech panów), pięciu panów, stu siedemdziesięciu trzech panów. Kwestia ta, czyli sposoby łączenia liczebników z rzeczownikami, jest szczegółowo omówiona w każdym podręczniku języka polskiego dla cudzoziemców.

Aby było trudniej, w różnych językach różna jest też składnia w ramach której konstruujemy frazy z liczebnikami. W szablonach przydaje się wówczas możliwość przestawiania kolejności podmienianych fraz; służą do tego znaczniki takie jak {0} albo $1. Przykład:
„{0} inflicts {1} to your resources and decreases your HP by {2} for every shop you visit” (źródło).
Jeśli to możliwe, warto zamienić znaczniki numerowane na opisowe:
„{Event.Saint.Nicholas.Day} inflicts {Wallet.damage.points} to your resources and decreases your HP by {HP.points} for every shop you visit”
– w takiej postaci niosą dodatkowy kontekst pomagający w przekładzie.

Kolejny temat, o którym do tej pory nie wspomnieliśmy – wyrażenia w różnych językach różnią się długością. Angielski jest zwięzły. Te same napisy po polsku zajmą na ekranie jakieś 30% miejsca więcej. Potrzebny będzie albo system budowania interfejsu ekranowego automatycznie zmieniający rozmiar kontrolek albo szablony zawierające zapas miejsca na dłuższe napisy.
Adresy pocztowe
Twój program musi obsługiwać adresy z całego świata? Witaj w piekle. Temat na osobną blogonotkę, tyle tu jest fałszywych założeń – że każda ulica ma nazwę, dom ma numer, numer nie jest ułamkiem, adres zawsze zawiera miejscowość, jeden budynek ma jeden kod pocztowy, że podział administracyjny jest niezmienny, że pięć linii tekstu zawsze wystarczy aby zaadresować list, że [tu dziesiątki innych przekonań].
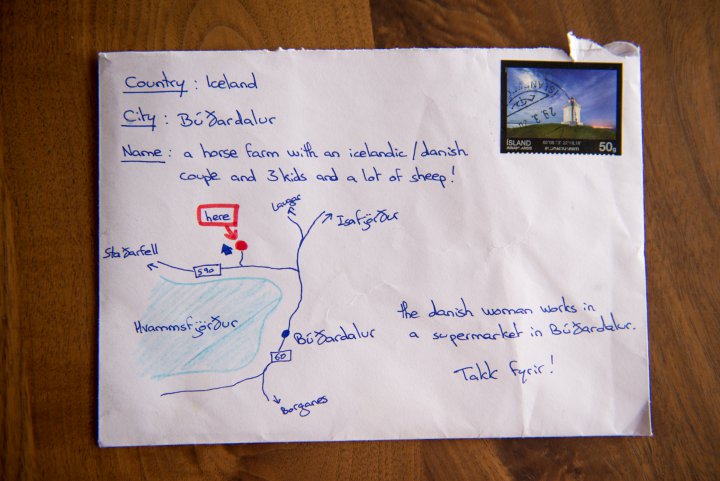
źródło: Loris Grillet
Jeśli musisz wysyłać coś na cały świat, spróbuj naśladować formularze Amazona. Nie mam lepszej rady.
Imiona i nazwiska
Twój program musi obsługiwać imiona i nazwiska ludzi z całego świata? Wiesz, ile alfabetów jest na świecie? Wiesz, ile z nich potrafi obsłużyć twój program? No nic, oto wybrane przykłady ze strony i18nguy.com, w formie obrazka. Powodzenia!
Dlaczego proces lokalizacji oprogramowania jest trudny
Znacie „Zasadę Kółka Graficznego”, ilustrującego pracę grafików?
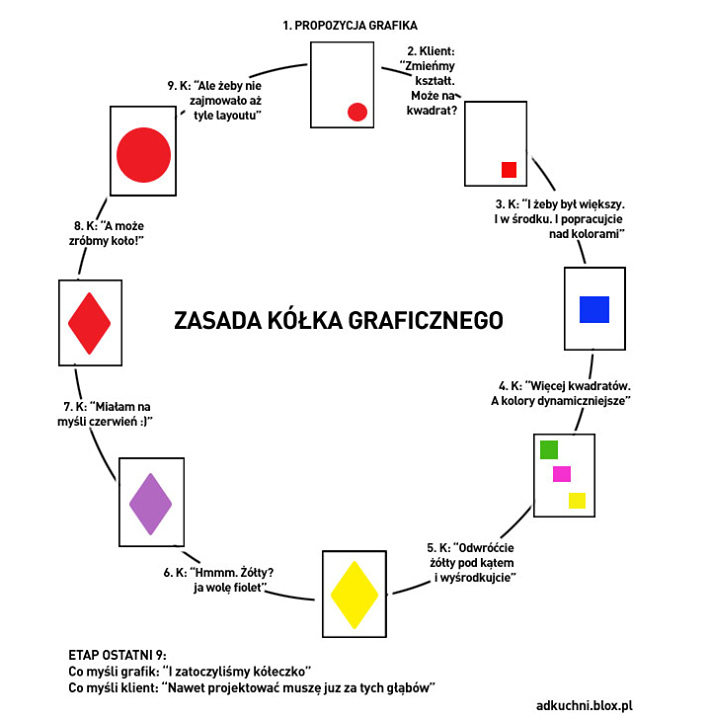
Teraz wyobraźcie sobie, że za te osiem czy dziewięć etapów odpowiadają cztery osoby z trzech stref czasowych i dwóch kontynentów, zaś ich zadanie jest opóźnione już w chwili rozpoczęcia (ktoś na wcześniejszym etapie prac zużył cały bufor zapasowy i jeszcze trochę, dzień jak co dzień, proszę się rozejść). Brzmi beznadziejnie?
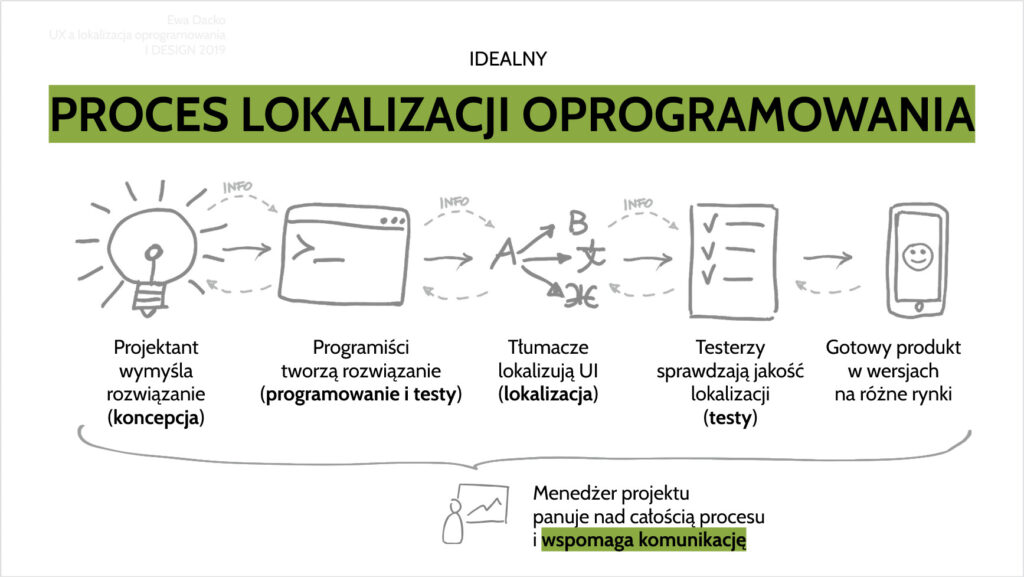
Bo przy tłumaczeniu oprogramowania im zwinniej (agile) tym trudniej. A już zwłaszcza, gdy robimy webówkę i szczycimy się procesem pozwalającym deployować zmiany na produkcję kilka (-naście, -dziesiąt) razy dziennie. Czemu? Ano, tłumacze z reguły nie są członkami zespołu a ich czas trzeba rezerwować z wielodniowym wyprzedzeniem. Podobnie – „językowi” testerzy i18n z reguły pracują ze swojego kraju i ich godziny biurowe mogą nie pokrywać się z naszymi.
Typowy proces poprawy usterki w tłumaczeniu może więc wyglądać następująco:
- zewnętrzny tester i18n zgłasza błąd tłumaczenia programu
- 16h przerwy, koordynator testów przychodzi do pracy
- kontakt z koordynatorem tłumaczy, rezerwacja czasu tłumaczy, przekazanie brakujących fraz
- tydzień przerwy, zanim obsłużone zostaną wszystkie potrzebne języki
- koordynator tłumaczy dostarcza uzupełnione tłumaczenia
- 4 dni przerwy, na koniec sprintu programista ma luzy
- programista wrzuca tłumaczenia i inicjuje deployment
- 17 dni przerwy, bo zewnętrzny tester i18n pracuje dla nas jeden dzień co dwa tygodnie a przy pierwszej okazji nie wyrobił się z retestem
- tester i18n potwierdza naprawę usterki
Czyli – miesiąc na realizację zadania, w którym rzeczywista pracochłonność zmian to minuta tłumacza i pięć minut programisty. Może być gorzej. Gdy zespół realizacyjny pójdzie na skróty, pliki z translacjami wymieniane są mailem, ludzie nawzajem nadpisują sobie zmiany a na końcu do repozytorium trafiają wynalazki o nazwie „final23_ostateczny_fix4”.
RTL czyli lustrzane odbicia
Wszystko, co napisałem powyżej, blednie wobec problemu LTR/RTL, czyli lokalizacji oprogramowania na potrzeby kultur i języków w których pisze się od prawej do lewej. Bo wiecie, nie chodzi tylko o pisanie – dla osób zanurzonych w takiej kulturze strzałka na przycisku „Wstecz” będzie wskazywała… w prawo. W prawym dolnym rogu znajdziemy też na ekranie Windows przycisk Start, paski przewijania okien znajdą się po lewej stronie i tak dalej.
Przyznam, że w swojej karierze nigdy nie dotarłem do tego etapu – zetknąłem się jedynie z tłumaczeniem aplikacji mobilnej na język chiński, co też generowało masę pytań, na które… nikt w zespole nie znał odpowiedzi.
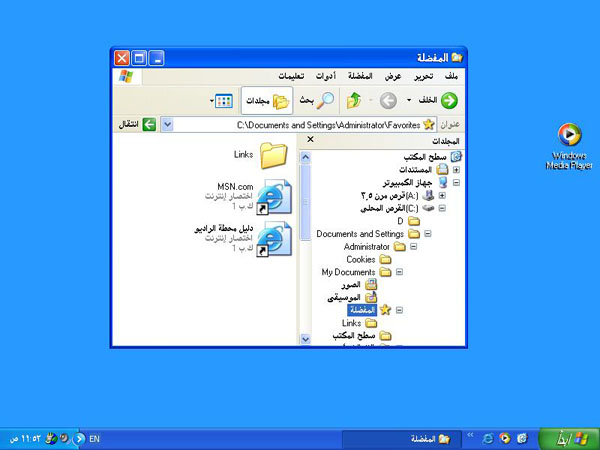
źródło: Microsoft
Przygotowanie oprogramowania z myślą o dwukierunkowości podwaja pracochłonność testów, zwielokrotnia koszt wytworzenia i stwarza masę problemów, które bez native speakerów ciężko zrozumieć, nie mówiąc o ich samodzielnym dostrzeżeniu. Bo tak: domyślnie tekst równamy do prawej, menu boczne ma wyjeżdżać z prawej, pasek postępu rośnie od prawej do lewej, ikonka ma być po prawej stronie tekstu a „rozwijaki” od comboboxa – po lewej.
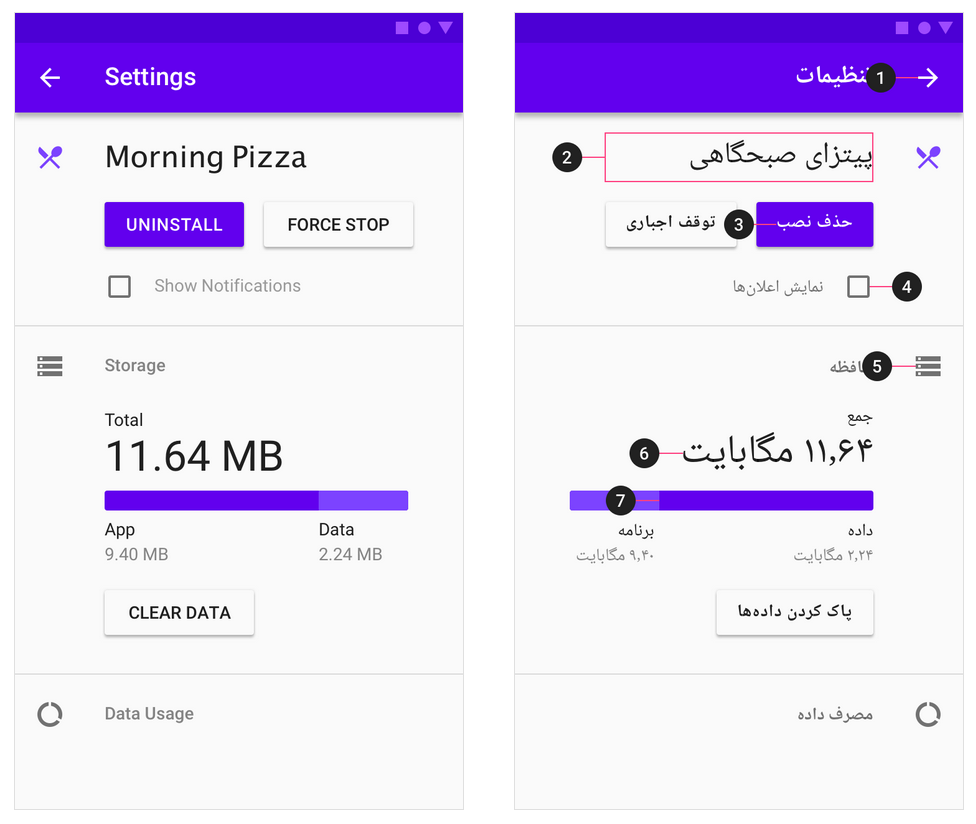
Ikonki i ilustracje w których kierunek ma znaczenie – obracamy:

Pozostałych: nie obracamy

WTEM! Pasek postępu w odtwarzaczach multimedialnych zawsze od lewej do prawej. Czemu? Bo niby odzwierciedla kierunek przesuwania taśmy w odtwarzaczu. Kiedy ostatnim razem używaliście taśmy magnetycznej jako nośnika?

Niech tłum odwali robotę
Webowe systemy wspomagające tłumaczenie bywają dostępne za darmo, więc twórcy oprogramowania mogą ulec pokusie i poprosić swoją społeczność o przygotowanie tłumaczeń na inne języki. Szanse na sukces są… w najlepszym razie niepewne.
Jeśli za translację wezmą się osoby nieznające specyfiki pracy tłumacza oprogramowania, będziemy mieli wszystkie opisane wyżej problemy i wiele innych, jak:
- niespójności słownictwa,
- niska jakość (literówki),
- usterki wynikające z braku dostępu do materiałów (np. streszczenia fabuły gry albo aktów prawnych wpływających na terminologię),
- brak kontaktu z zespołem programistów,
- znudzenie i porzucanie projektu w losowym momencie,
- trolling (np. ukryte wulgaryzmy)
Z opisu prawdziwych doświadczeń z crowdsourcingiem wynika, że największym problemem jest niespójność i nieterminowość. Szanse sukcesu mocno rosną, gdy każdy z języków będzie miał zaufanego opiekuna/lidera mającego bliskie relacje z zespołem produkcyjnym.
Czego nie da się przełożyć
Na przykład porządku prawnego. Seriale „Suits” albo „Better Call Saul” potrafią nieźle namieszać w głowach polskim widzom, bo anglosaski system Common law nie ma wiele wspólnego z polskim prawem, różnice dotyczą nawet podstawowych pojęć. Podobnie jest z systemami podatkowymi.
Pewne problemy pojawiają się też przy przeliczaniu wartości z imperialnego systemu miar na metryczny. Pół biedy, gdy stopy i cale odnoszą się do wzrostu bohatera. Gorzej, gdy mamy do czynienia z opisem technologii, precyzja podawanych wartości ma znaczenie a cale czy galony przeliczamy na centymetry lub litry.
Tworzenie oprogramowania a polityka
Dwie dość odległe rzeczy, prawda? Niby tak, ale nie wtedy, gdy w grę wchodzi i18n. Globalne korporacje mają spory zgryz, bo chciałyby robić biznesy wszędzie i z każdym, tymczasem wiele państw będących w konflikcie oczekuje opowiedzenia się Googlów czy Microsoftów po ich stronie.
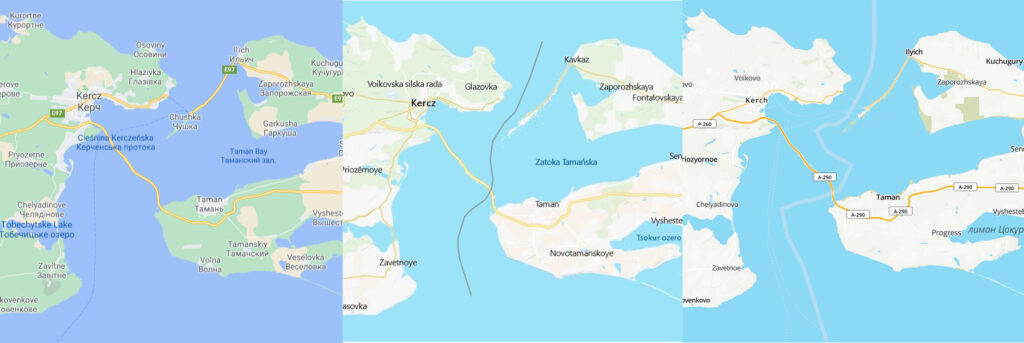
Przykład – półwysep Krymski. Ukraiński czy rosyjski? Rysować jedną granicę, dwie czy żadnej? Kreska zwykła czy przerywana?
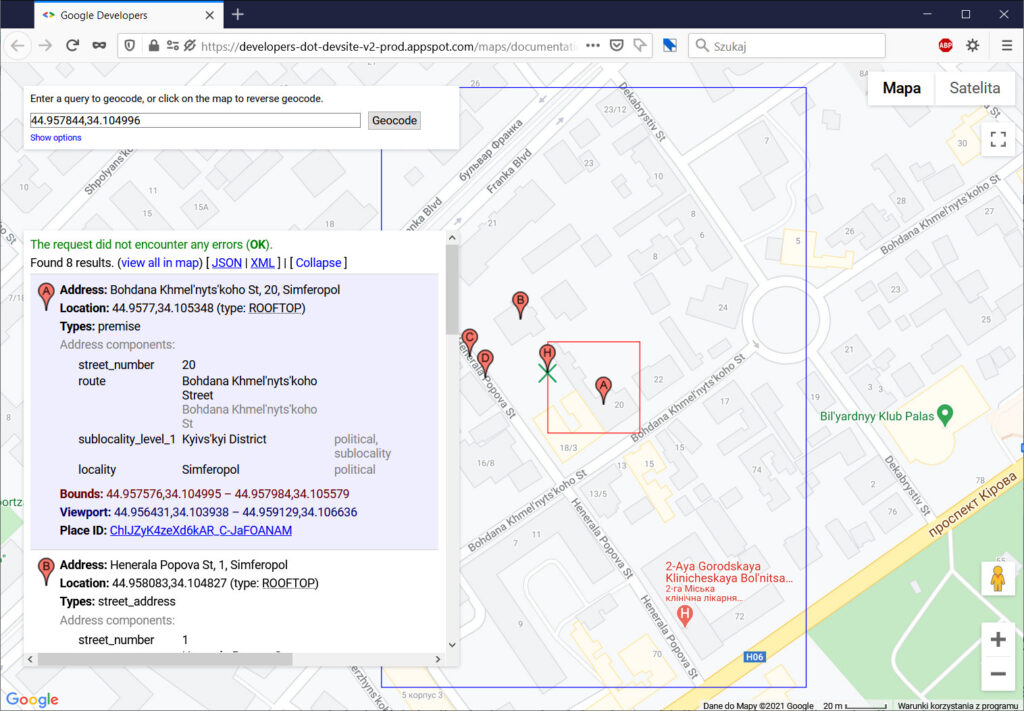
Jeśli chodzi o API do odwrotnej geolokalizacji, będzie prościej. Użytkownik pyta o jakieś współrzędne, API poda numer domu, ulicę, miasto i… tyle. Nazwa państwa jest zniknięta. W sumie i tak dobrze, bo przez kilka lat geolokalizacja na Krymie nie działała w ogóle.
W słowach Pisma czytamy: „Żaden sługa nie może dwom panom służyć. Gdyż albo jednego będzie nienawidził, a drugiego miłował; albo z tamtym będzie trzymał, a tym wzgardzi. Nie możecie służyć Bogu i Mamonie”. Cóż, przydałaby się gwiazdka i przypis, że nie dotyczy korporacji – one służbę dwóm panom mają przećwiczoną. Geolokalizacja pozwala prezentować różne wersje mapy użytkownikom z różnych krajów.
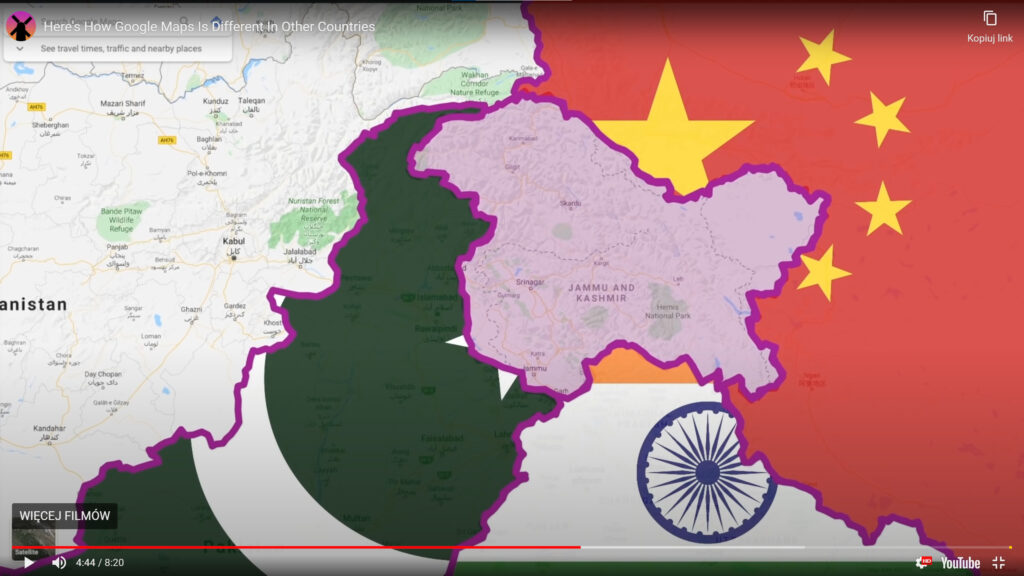
Taki problem występuje w Kaszmirze, do którego prawa roszczą sobie Indie, Pakistan i Chiny. Ten film pokazuje dzikie fikołki, którymi Google Maps stara się zadowolić trzy mocarstwa nuklearne zamieszkiwane przez miliardy potencjalnych użytkowników.
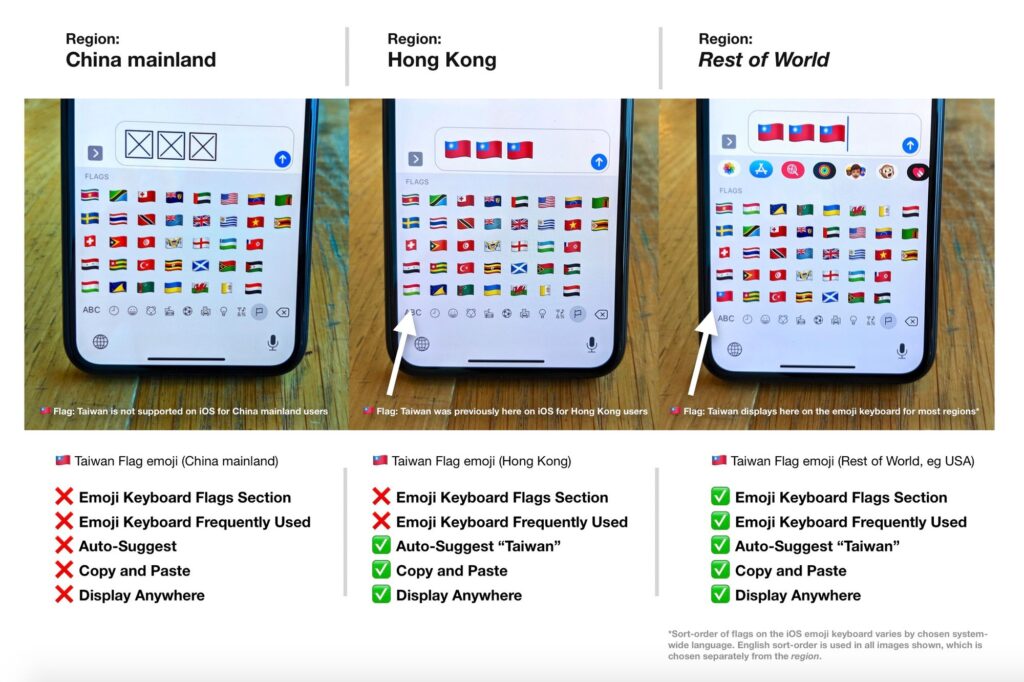
Inny przykład – flaga Tajwanu na iPhone’ach. Dla użytkowników w Chinach – nie istnieje. Dla użytkowników w Hong-Kongu – nie występuje na liście flag. Dla całej reszty świata – istnieje.
Nagroda na końcu drogi
Jeśli program, nad którym pracujesz, okaże się sukcesem, czeka cię praca nad… wersją chińską. Będziesz patrzyć na tłumaczenia złożone z chatek (屋) i choinek (聖誕樹) w których nie dostrzeżesz nawet najbardziej oczywistej i spektakularnej usterki.
Jeśli program okaże się spektakularnym sukcesem, czeka cię praca nad wersją… arabską. Nauczysz się, że wszystko, co było w interfejsie użytkownika kotwiczone do strony prawej lub lewej, należy nauczyć się kotwiczyć do strony początkowej lub końcowej, obrazki dostarczać w dwóch wersjach i tak dalej. Napisy tradycyjnie w formie szlaczków (ممر المشاة)
Słowem – nie będzie nagrody. Nie będzie końca.
Na zakończenie
To wszystko jest trudne. Microsoft miał tysiące specjalistów i 30 lat na ogarnięcie tematu a i tak w wielu miejscach poległ. W wersjach Windows wcześniejszych niż dziesiątka można było na przykład włączyć pseudo-locale przygotowane tak, by były jak najbardziej udziwnione. Dzięki temu od razu było widać miejsca, w których pominięto wywołania systemowych funkcji formatujących daty, liczby czy wartości pieniężne. Niestety – po ich włączeniu psuły się nie tylko aplikacje innych firm, ale także Excel, Visual Studio, Podgląd Zdarzeń i wiele innych. To jest naprawdę, naprawdę trudne.
Ty, lokalizując oprogramowanie, będziesz mieć mniej czasu i mniej zasobów. Należy robić to co się da tak dobrze, jak się da. Cudów nie będzie. Użytkownik z Nepalu (नेपालबाट प्रयोगकर्ता) wybierze program do obsługi podatków (करहरू आवेदन) autorstwa nepalskich programistów i… wszyscy możemy z tym żyć.
Nie próbuj zrobić wszystkiego dobrze za pierwszym razem. Daj użytkownikom możliwość wygodnego zgłaszania błędów, odpowiadaj im i naprawiaj usterki zgodnie z priorytetami a… jakoś to będzie. W wielu przypadkach nawet niedoskonałe tłumaczenie będzie o niebo lepsze, niż jego brak.
O co chodziło z tą darmową ochroną danych jesień?
Gdy dysk twardy gruchnie o ziemię a głowice uderzą w wirujące talerze, mamy sporą szansę na uszkodzenie danych lub całkowite zniszczenie dysku. W laptopach montuje się więc akcelerometr wykrywający upadek – w takim przypadku głowice w ułamku sekundy wyjeżdżają poza obręb talerza, by zmniejszyć ryzyko uszkodzeń.

autor: Gough Lui
W laptopach Dell odpowiadał za to program o opisowej nazwie „Free fall data protection” czyli „ochrona danych przy upadku swobodnym”.
Free – swobodny ale także darmowy
Fall – upadek ale także jesień
Data – dane
Protection – ochrona
Innymi słowy: “darmowa ochrona danych jesień”.
Autor
Tomasz Zieliński: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing. Prowadzi serwis Informatyk Zakładowy, gdzie miał pisać (cytat) o bezpieczeństwie w internecie dla każdego, a w praktyce pisze, co mu przyjdzie do głowy.

{kind=link}
{kind=link}