Na czym polega przewaga człowieka nad silnikiem tłumaczenia maszynowego?
Człowiek rozumie.
Jak wyjaśnił prof. Marcin Miłkowski na Konferencji Tłumaczy 2019, żaden z dostępnych systemów MT tak naprawdę nie modeluje znaczenia, sensu, treści – wszystkie oparte są na jak najlepszym odwzorowaniu tekstu źródłowego w tekst docelowy, ale na zasadzie wyznaczenia najwłaściwszych słów i ustawienia ich w najbardziej poprawne zdanie; jeśli przeniesie się przy tym sens, to niejako przypadkowo. Owszem, NMT najnowszej generacji potrafi operować na synonimach, ale dlatego, że znajduje je w danych treningowych. Tylko my wiemy, że przypowieść o dysonansie i kobiecie lekkich obyczajów niesie w języku polskim taką samą treść, jak coś mi tu kurwa nie gra.
Mówiąc o zastosowaniach tłumaczeń maszynowych, wymienia się zwykle dwa:
- Postedycję, czyli użycie MT jako podpowiedzi dla tłumacza profesjonalnego.
- Zastosowanie MT bez weryfikacji ludzkiej, żeby odbiorca mógł mniej więcej zrozumieć o co chodzi.
Rzadko mówi się o zastosowaniu trzecim, a to właśnie ono pozwala najlepiej wykorzystać przewagę człowieka nad maszyną. Chodzi o tworzenie tekstu w taki sposób, że piszemy go w języku źródłowym (zwykle własnym) i wykorzystujemy MT do podpowiadania tłumaczenia, które następne poprawiamy:
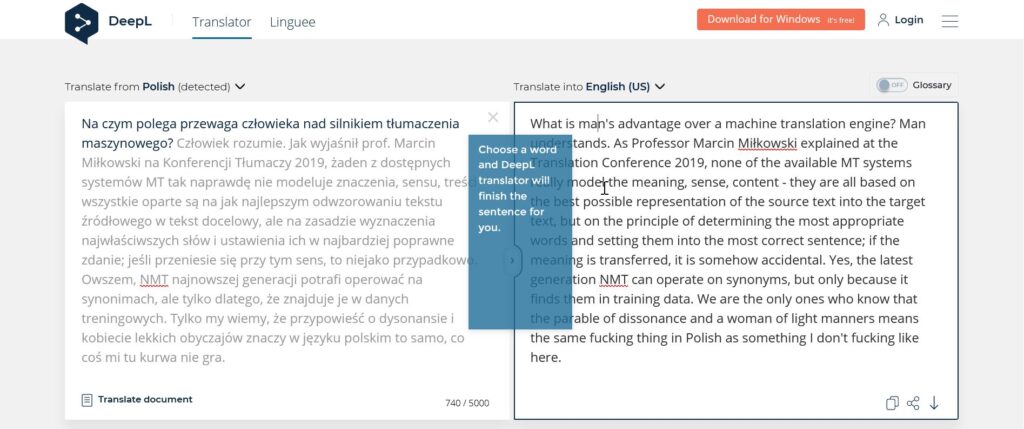
Od strony technicznej można to załatwić różnie:
- przepuścić cały dokument przez MT i obrabiać go dalej u siebie,
- skorzystać z synonimów podpowiadanych przez maszynę, jeśli ma taką funkcję (na załączonym obrazku zaczęłabym od zmiany „man” na „human”).
Przyznaję, że od czasu do czasu korzystam z takiej „leniwej” techniki pisania tekstów w języku obcym, i nie jestem w tym odosobniona. Znajomy informatyk bardzo sobie chwali połączenie DeepL i Gramarly jako kombajnu wspomagającego tworzenie artykułów naukowych po angielsku. Zaprzyjaźnieni naukowcy – geolog i teolog – w podobny sposób tłumaczą streszczenia swoich prac na angielski lub rosyjski. A ostateczną motywacją do spisania tych obserwacji stała się dla mnie firma tworząca aplikacje internetowe, w której proces lokalizacji przebiega jakoś tak:
- Zasoby interfejsu powstają w języku polskim, tworzą je Polacy.
- Następnie podtłumacza się je na kilka języków przez wtyczkę do Google Translate.
- Tłumaczenie poprawia osoba dobrze znająca dany język.
- Na koniec każda wersja językowa, włącznie z polską, jest – rzecz jasna – testowana przez native speakera.
Co łączy powyższe przypadki?
- Autor dokładnie wie, co chce powiedzieć. W przeciwieństwie do tłumacza-postedytora, nie musi analizować strony źródłowej – ma ją w swoich neuronach, zanim napisze pierwsze słowo.
- Autor zna język docelowy wystarczająco dobrze, żeby odrzucić tłumaczenia całkiem błędne.
Kiedy spełnione są te dwa warunki – zastosowanie MT wchodzi na nowy poziom. Wykorzystujemy maszynę przede wszystkim jako korpus obcego języka, z którego czerpiemy frazy, jakie być może nie przyszłyby nam do głowy. Czy trend „leniwego pisania” okaże się najbardziej przyszłościowym zastosowaniem MT? Zobaczymy. W każdym razie ryzyko błędu jest tu z pewnością niższe niż w przypadku klasycznej postedycji czy zgoła wrzucania surowej „maszynówki”.